GenAI: I don't care what it is and you shouldn't either

When did you first hear the term GenAI or GenerativeAI? A year ago or 2 years maybe. Now check out this video generated with the help from an AI model called DeepDream by Google.
DeepDream Grocery Generated video
When do you think that was made? Would you be surprised if I told you that it dated back to 2015? That’s right almost 7 years before the term GenAI was even coined, researchers were making generative models that could do this. So is this GenAI or is it something else? Well read on and we’ll find out.
Who am I
When I first started out in machine learning in 2017 I was hung up with terminology. My company had a hunch that we could use AI somehow to make use of the large amounts of data that we were collecting and provide our users with insights and recommend actions to take. The problem was that I hadn’t a clue what I was doing and I didn’t know where to start. I somehow convinced myself that I needed to get a clear understanding of what the differences were between AI and Machine Learning. Days would go by trawling the internet trying to find the answer. Eventually, I stumbled upon the Andrew Ng’s Machine Learning Coursera course and I started to understand what Machine Learning was and how it could be applied. This led on to more formal training and years of practical experience and now I’m a proficient data scientist. I’m not about to unlock the secrets of AGI, but I’m perfectly capable of creating custom deep learning models from scratch, reading and writing research papers and making commercially successful AI software. The point I want to make is this: Somewhere along the way I realised that the question I was trying to answer at the outset mattered the least. I didn’t need to know the difference between AI and Machine Learning. I just needed to know how to use the tools available in order to solve the problem at hand. Having said all that, let me give you my take on how to define these terms.
Artificial intelligence
The term Artificial intelligence hasn’t always had the allure that it enjoys today. Back in the early 2010’s the situation was quite different. Andrej Karpathy ( ex OpenAI, Tesla, Stanford and all round good guy) described what it was like to join an AI University course in 2011:
“Back then you wouldn’t even say that you joined AI by the way, because that was like a dirty word, back then it wasn’t even deep learning … it was machine learning. That was the term you would use if you were serious. But now AI is ok to use I think” - Andrej Karpathy
You know when you watch a politician and they are asked a very specific question and they give a very vague answer? “What percentage of GDP are you going to spend on healthcare minister?”, “We are committed to providing the best healthcare for all our citizens and we will do.. blah blah blah”. Well ask a data scientist what AI is and you will get a similar answer. Richard Sutton, who literally wrote the book on Reinforcement Learning, said in a 2023 talk on the reward hypothesis:
“The field of artificial intelligence was famous for not defining what intelligence is or what artificial intelligence is… for so long it just refused to do it”. - Richard Sutton
You see the problem is that the things we use to build AI systems keep on changing as new techniques are developed and the world around us changes. We can’t say that AI is any one particular thing because the next year it might not be. So by keeping it vague we can avoid having to change it’s definition and just accept that it is a moving target of whatever we consider to be intelligent at the time. Today, for all intents and purposes AI is Machine Learning.
Machine Learning
So, what is Machine Learning? Machine Learning is the process of using data to teach a computer program how to complete a particular task without being coded explicitly how to do it. But how is this possible you ask? It must be witchcraft! Well no it’s just maths. They are mathematical functions that take in a number(s) and output a number(s). Of course I’m simplifying things a lot, but essentially that’s what these things are and we call them models. Let’s take a simple example. Imagine that you have an online real estate website and you want to predict the price of houses based on their square footage. What information do you have available to you? Well you have the prices and square footage of houses that have been sold in the past. What you can do is record these prices and square footages and put them in a table. When you want to predict the price of a new house your model will accept the square footage as an input, and then lookup in the table to find the price of a house with the same or similar square footage and that will be your prediction. Believe it or not this is the basis for a real machine learning algorithm and it’s called k-nearest neighbours. We haven’t defined any rules in code to tell the program about what the price of a house should be based on the square footage. We have just given it some data and it has “learned” the relationship.
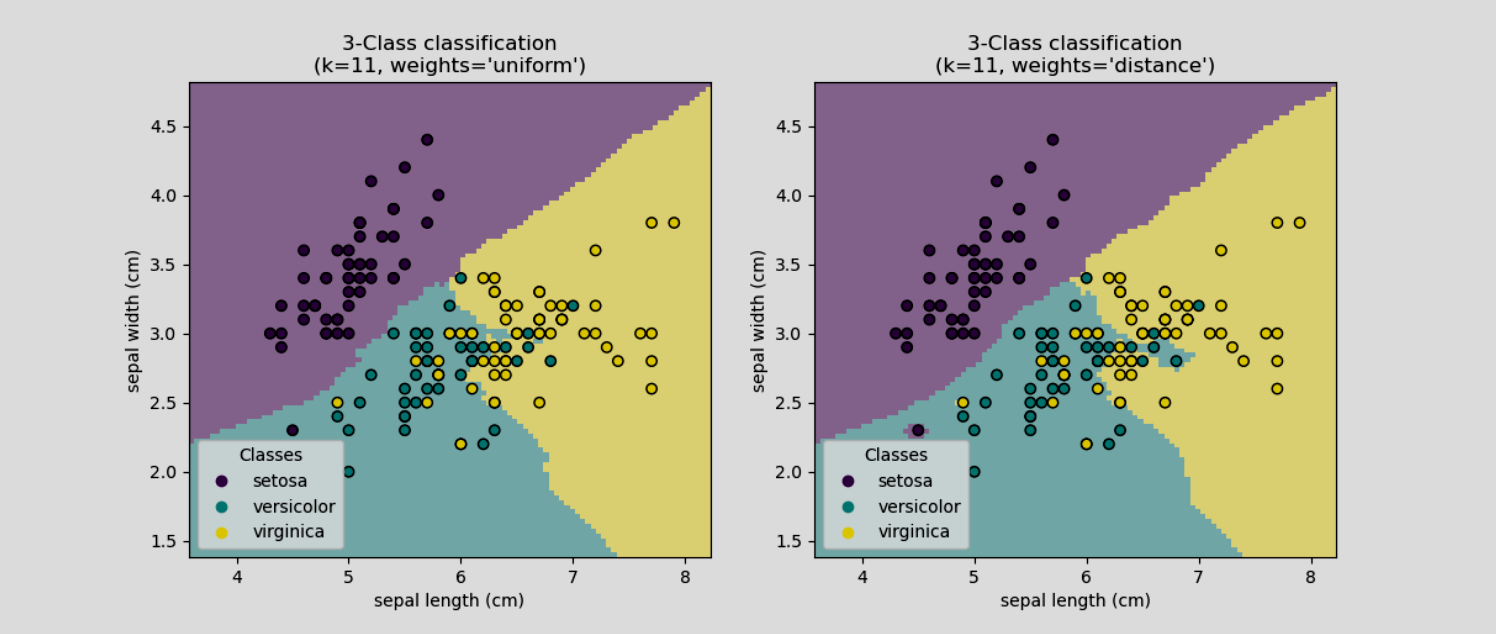 K-Nearest Neighbours classifying Iris types
K-Nearest Neighbours classifying Iris types
Machine learning starts and ends with the data. If you feed your model with with a steaming pile of horse manure then guess what you’re going to get out the other end. Also, there isn’t a machine learning algorithm anywhere in the world that is going to predict a fair coin toss better than 50% on average. That’s just how it is, it can’t predict the lottery or any other random event, so if your data contains no predictive information then you’re going to be disappointed.
There are many different types of machine learning algorithms and most of the ones we call classical machine learning have been developed to specialise in solving particular type of problem. There are algorithms that are good for forecasting future values in time-series, for fraud detection, for automatically sorting things into categories and so on.
To solve a particular problem you need to choose an appropriate algorithm for the job. To some extent the exception to this rule is a neural network which is more flexible and can be used for a broad range of tasks, and in some, but certainly not all situations they produce better results.
Neural Networks / Deep Learning
Funny thing thing is that the idea of neural networks has been around since the 1950s, but for the most part they were confined to the academic world because at a practical level they we were almost completely useless. In fact they became so irrelevant that MIT considered dropping the subject altogether from its AI curriculum.
“It was 2010, we were having our annual discussion about what to dump …. to make room for some stuff. And we almost killed off neural nets… Nobody had ever made a neural net that was worth a dime for doing anything” - Patrick Winston, MIT
Now this all changed in 2012 when a team of researchers from the University of Toronto entered a competition called ImageNet, the aim of which was to classify objects in images. Their model happened to be a neural network and it beat the competition by a country mile.
 ImageNet Image Classification Competition winners AlexNet - University of Toronto (2012)
ImageNet Image Classification Competition winners AlexNet - University of Toronto (2012)
It’s a well known story so I won’t go into the details, but the important thing was that researchers had been able to unlock the potential of the neural network by training it with a lot of data and modifying the structure of the model by adding more things called layers. Layers are just functions, they’re just arranged sequentially so that the result from one function is used as the input into the next. To add more layers is to make the model deeper. The deeper the model, the better it performed at these Image classification tasks. So out with the old and in with the new, we rebrand Neural Networks as Deep Learning and hey presto we have the hottest thing in AI.
Now we’ve known for a long time that if we change the structure of the functions in the layers then we can tailor the model to perform better at specific tasks. A lot of research in this area has been focused on finding ways to structure these layers to make the model perform better, or more efficiently or for a wider range of use cases. When these new structures are developed we refer to them as model architectures. Back in the mid 2010’s a lot of academic research was either focused on computer vision (CV) for tasks involving images like object detection or focused on natural language processing (NLP) for tasks like sentiment analysis and language translation. These respective fields had their own preferred model architectures, but between 2013 and 2020 there was an explosion of research in the field as we tried to mix and match various ideas and apply them to specific problems.
Google created an architecture that was capable of annotating images with a short description by combining models suited for NLP with models for CV.
 Image Captioning Show and Tell - Google (2015)
Image Captioning Show and Tell - Google (2015)
Google DeepMind found a way of combining neural networks with the lesser known field of Reinforcement Learning to create models that could play games like Go and StarCraft II at a human level.
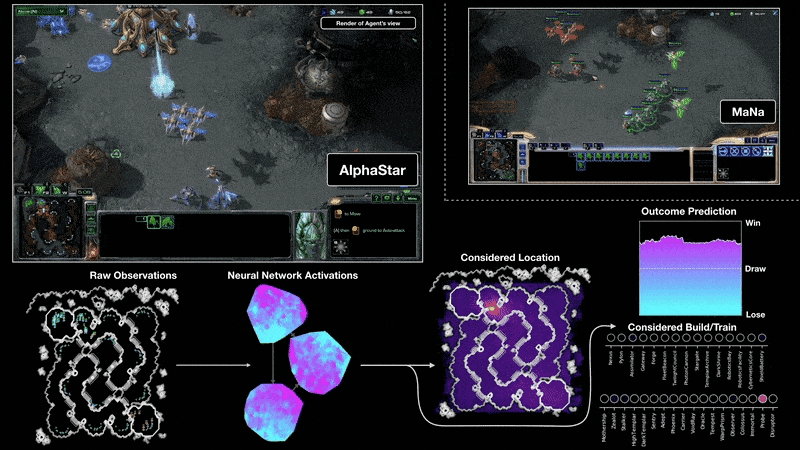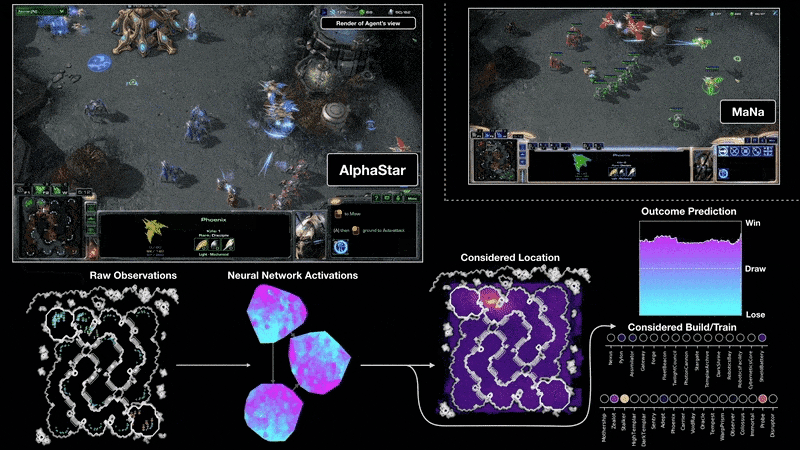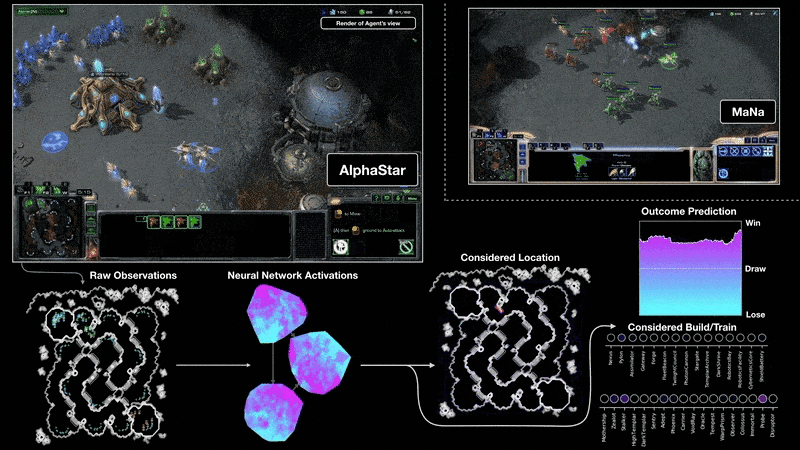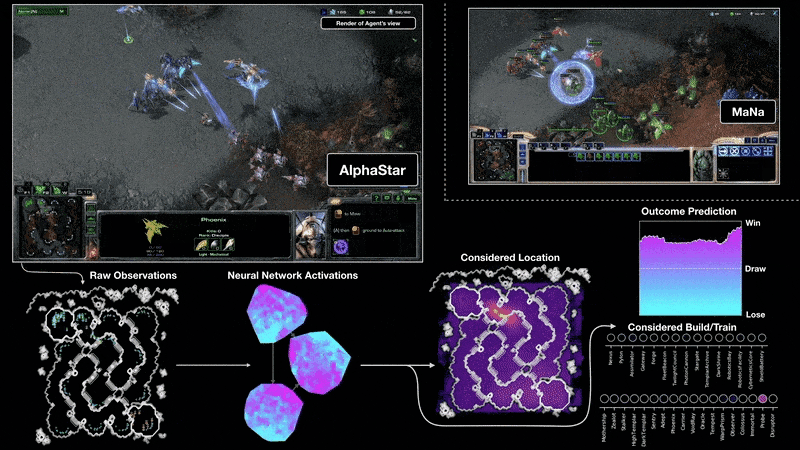 Playing StarCraft II with AlphaStar Google DeepMind (2019)
Playing StarCraft II with AlphaStar Google DeepMind (2019)
In 2017, in probably the most cited paper in the field of AI, researchers at Google Brain introduced a new type of architecture called the Transformer. It’s designed purpose was to perform “sequence to sequence” such as language translation, but we subsequently found that it performed very well on a range of tasks and today it is used in, amongst other things, Large Language Models (LLMs).
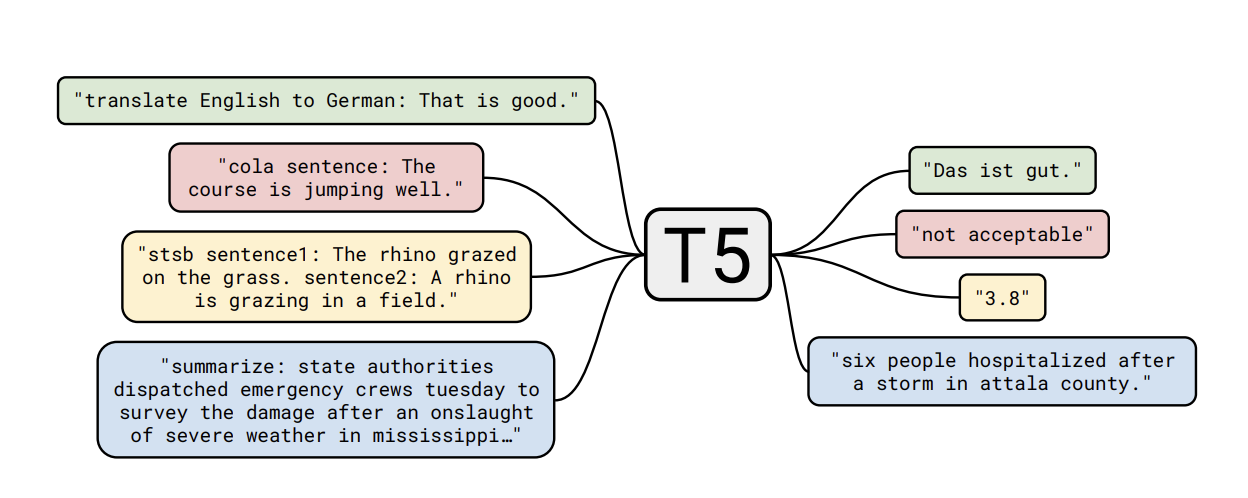 Text Translation T5 Transformer - Google (2019)
Text Translation T5 Transformer - Google (2019)
For some time we had known that if you took the best computer vision models that had been trained with a lot of data, you could then take a handful of images about a particular subject that it hadn’t previously been trained on and train a part of the model in a process called Fine Tuning. Amazingly it would then become extremely capable in that new subject. Somehow the model was able to transfer its general knowledge of images and apply it to a new field with only a few examples. This ability was called transfer learning and models trained like this became known as few shot learners. In 2018 Jeremy Howard (FastAI) and Sylvain Gugger pioneered a method of using transfer learning with NLP models meaning that a language model could be fine-tuned to produce a family of models that performed well at tasks like sentiment classification, topic classification and question classification.
Additionally, numerous approaches were developed to create models that could generate synthetic audio, text and images which formed the basis of what we call Generative AI today.
Generative AI
Now it’s worth mentioning here that up until a couple of years ago when ChatGPT came along, Generative AI was not a term with it’s own identity. We had generative models which were just a part of deep learning and there were a lot of ideas that were proposed to generate synthetic text and images. In 2014 Ian Goodfellow developed a model called GANs (Generative Adversarial Networks) which could generate images using two models which would compete against each other, with one to generate “fake” images and the other to spot which images were fake and which were real.
 GAN Generated Images Montreal University (2014)
GAN Generated Images Montreal University (2014)
Andrej Karpathy, who I mentioned earlier, developed a model called CharRNN which was able to generate text that was almost indistinguishable from real text. A mini version of the code is about 100 lines long and is still on Github today.
 CharRNN Generated Latex - Karpathy (2015)
CharRNN Generated Latex - Karpathy (2015)
In 2016 Google DeepMind developed a model called WaveNet which could generate audio and then the same researcher went on to develop a model called PixelCNN which could generate images.
![]() PixelCNN Generated Images - Google Deepmind (2016)
PixelCNN Generated Images - Google Deepmind (2016)
Now these models used common architectures that were popular at the time, but the difference was that they used their own predictions as input to the model to generate new prediction in a process called Autoregression. In 2019 Stability developed a very different technique called Diffusion which was able to generate images which led to the popular image generation model, Stable Diffusion.
So how does ChatGPT fit into all this? Well OpenAI started developing their Generative Pretrained Transformer (GPT) models in 2018 with the aim of creating few shot and zero shot models that could perform a wide range of language tasks. Zero shot meaning that the model didn’t have to go through the fine tuning stage to perform a particular task (ie you could use the same model to perform different tasks). Each successive GPT model used more training data, and a larger model (ie more layers).
GPT-1 demonstrated some potential for zero shot learning, but achieved great results with fine tuning. GPT-2 went further achieving better success with zero shot learning confirming that if a model is trained on a sufficiently large corpus of text data then the kind of tasks we want language systems to do will be learned implicitly. GPT-3 really started to explore the use of prompts to perform tasks in their zero shot model and It outperformed the best fine-tuned model in question answering. ChatGPT was a further evolution and added fine tuning, and a new technique from the field of Reinforcement Learning to give it this chat assistant question and answer like capability.
Since then there has been a rush by companies like Google, Meta and Anthropic to develop their own LLM models to compete with ChatGPT. But at a cost of half a million dollars plus just to pay for the electricity bill to train these models it’s not exactly what you might call accessible. This has however, led to innovations that are within reach of most organisations. Innovations like RAG which enable models to search and work with a company’s documents, and fine-tuning, which train a model to imitate a specific style or persona.
So many terms
So what’s the problem. Well the problem is that the term Generative AI has been broadened to include all the models and techniques that have been used to generate synthetic data plus the new techniques are associated with LLM’s such as fine-tuning and RAG, plus anything else that that wants to jump on this hype train. But why do I care about all this? Well I’ll give you an example. One of my areas of interest is time-series forecasting. Given a sequence of historical events predict what will happen in the future. Now it may surprise you but we can and do use exactly the same Autoregressive model types that are used in Generative AI, but we’re not generating synthetic data we’re predicting the future and so on that basis I don’t think we should describe what we’re doing as Generative AI. However, an active area of research in our space uses LLM’s or LLM like models to do the forecasting. TimeGPT from Nixtla is just one example and was the first to do this, and essentially adopted the ethos of using large datasets and transfer learning. Now they describe this as Generative AI, which of course they are perfectly entitled to do, but now I have a conundrum. If I’m using the same types of models as those used in Generative AI and now there is precedent for others in our field to describe what we’re doing as Generative AI, then shouldn’t I follow suit? And herein lies the problem. AI vendors are being pressured into adopting the Generative AI term because it’s been marketed so successfully that everyone wants to join in. So naturally its definition is destined to become more fuzzy and bloated over time as more businesses look to associate themselves with the most successful term since Crypto.
I’m not advocating a definition of the term either, because here’s my take:
Just as I realised the difference between AI and Machine Learning was insignificant, so too is the distinction between Generative AI, Deep Learning, and Machine Learning.
I don’t care what we label these things and I don’t think you should either. What I care about are performance metrics that tell me how well a model is able to complete a task. I care about what problems a model is capable of solving. I care about how much it costs to train and deploy. I care about how frequently it will need to be updated. I care about how robust it is and how well I can trust it. I care about how it can be integrated into my existing systems, and I care about what resources and skills are going to be required to maintain it. And so I think it would be breath of fresh air if we could just focus a little bit more on these things and not get too hung up on the terminology.
So back to DeepDream, does it qualify as GenAI or not? Somewhat predictably my answer is: I don’t care… let’s just enjoy it for what it is - a fun, quirky and very trippy little video.