
Teacher Forcing: A look at what it is and the alternatives
1. Introduction
In sequence modelling we often use a model that is auto-regressive. That is to say that the output of one time step serves as the input into the next time step. This concept us used in many generative models regardless of their architecture. In theory the output of the model is infinite and so we can keep feeding the output back into the model to generate as much as we like.
The problems start when we come to train the model. How do we train a network that is supposed to generate output based, in part, on it's own output? The answer is teacher forcing.
2. Teacher Forcing
There are often terms that are used in machine learning that are not immediately obvious what they mean. I've often thought teacher forcing is a strange term and for some reason evokes images a stern looking man with a gown and mortar board banging a cane down on a desk whilst demanding a room of petrified pupils to recite their times tables. Fortunately it's not quite as scary as that and is actually a pretty simple concept. First proposed by Williams and Zipser [1] the idea is to use the ground truth output as the input to the next time step during training. This means that the model is always being trained on the correct input and so should learn to generate the correct output.
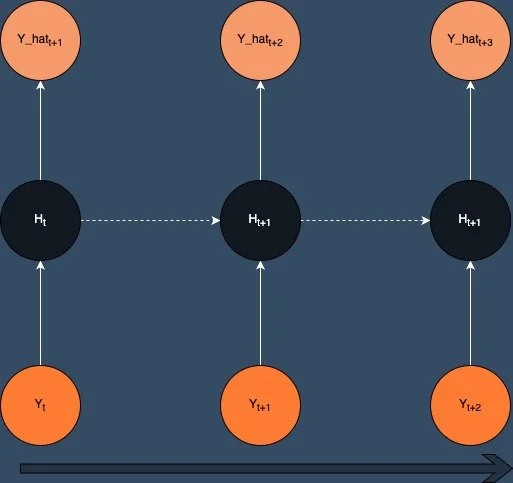
Teacher Forcing
In code this is a very natural thing to do as we can set the target to be the feature vector of a sequence shifted right by one time step.
data = torch.rand(10, 5, 3) # 10 sequences of length 5 with 3 features
X = data[:, :-1, :] # remove the last time step
y = data[:, 1:, :] # shift the target right by one time stepYou can see that the input and output are the same length and the output is the input shifted right by one time step. Now you just feed the input into the model and compare the output to the target with your favourite loss function and you're good to go.
3. Free Running
So here's thing. Our network learns to generate one time step at a time and it's not learning to generate sequences of multiple timesteps. This leads to a problem when we want to use the model to generate sequences any error in the output of one timestep just gets compounded in future timesteps and before long the output is complete garbage. Alex Graves made a great presentation for NeurIps 2018 [2] where he talked about teacher forcing as leading to potentially brittle generations and myopic representations.
An alternative is to use the output of the model from each timestep as the input to the next timestep during training and then backpropogate through each timestep in the sequence. The training in this setup now replicates the inference task and so the model should learn to generate better sequences across multiple timesteps. The downside is that this is a much more difficult task and models would normally require good initialisation strategies, careful hyperparameter tuning and tricks like gradient clippling to get this to work and avoid exploding or vanishing gradients.
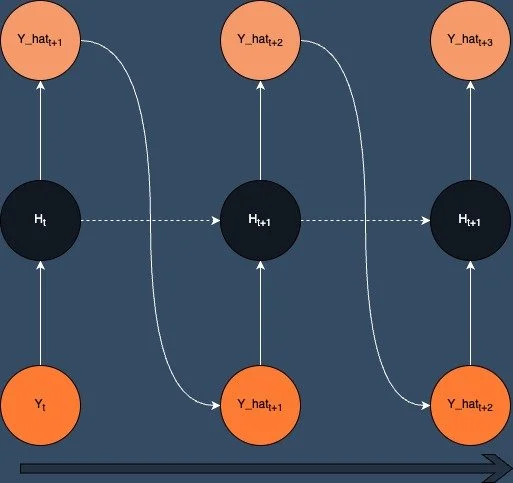
Free Running
Now this approach is fine so long as the model is producing point predictions of a continuous variable as all you need to do is take the raw output of the model and use it as the input to the next timestep.
However for discrete cases where the model is producing a probability distribution over categorical classes as would be the case in a language model or even a WaveNet model where continuous values are quantized to produce a categorical distribution then things start to get more complicated. The problem is that to obtain your next input you need to sample from the distribution and normally in the training process you would use a greedy approach and use a softmax to produce the probability distribution and then an argmax to select the index of the most likely class. However this is not differentiable and so you can't backpropogate through it. Now you could just detach the outputs from the graph at each timestep to use as the input into the next timestep, or alternatively you could use a reparametrisation trick to make the sampling differentiable using the Gumbel-Softmax trick.
The issue can be extended into any model where the output is a distribution, for example in the DeepAR model[3] produces the parameters of a Student-T or a Negative Binomial distribution from which you sample to fetch the point predictions and so the same problem exists albeit the reparametrisation trick to make the sampling differentiable is slightly different.
To some extent it looks to me like this is still an open question and I'm quite suprised by the lack of research in this area. As of 2024 the question of whether to detach the outputs from the graph before using them as the input seems to me to be a piece of the puzzle that is missing.
4. Scheduled Sampling / Curriculum Learning
In 2015 Bengio et al proposed an approach they called Scheduled Sampling [4] which essentially uses a combination of the two methods in the training process. Using a schedule where the model is trained primarily with teacher forcing during early phases of training then gradually increasing the proportion of the time the model is trained with it's own output as input.
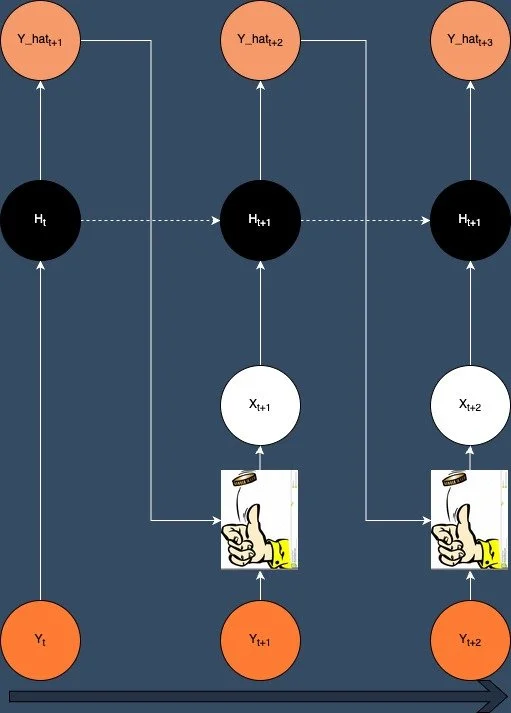
Curriculum Learning
It's an interesting approach, but my experience is that it speeds up the training time, but doesn't necessarily improve training stability. A study by Teutsch and Mader in 2022 [5] examined the effects of generalising the schedule of the curriculum to evalute the effects of a contstant ratio and increasing ratio of teacher forcing and free running during training in addition to the original schedule of descreasing the teacher forcing ratio.
5. Professor Forcing
In 2016 Lamb et al introduced an approach called Professor Forcing [6] which attempted to address the mismatch between teacher forcing training and sampling at inference time which they refer to as free-running by using a GAN based architecture. They proposed using the standard teacher forcing setup but adding a discriminator to the system that would try to distinguish between the output from using teacher forcing and the output from free-running (ie using predictions as the input to the next timestep).
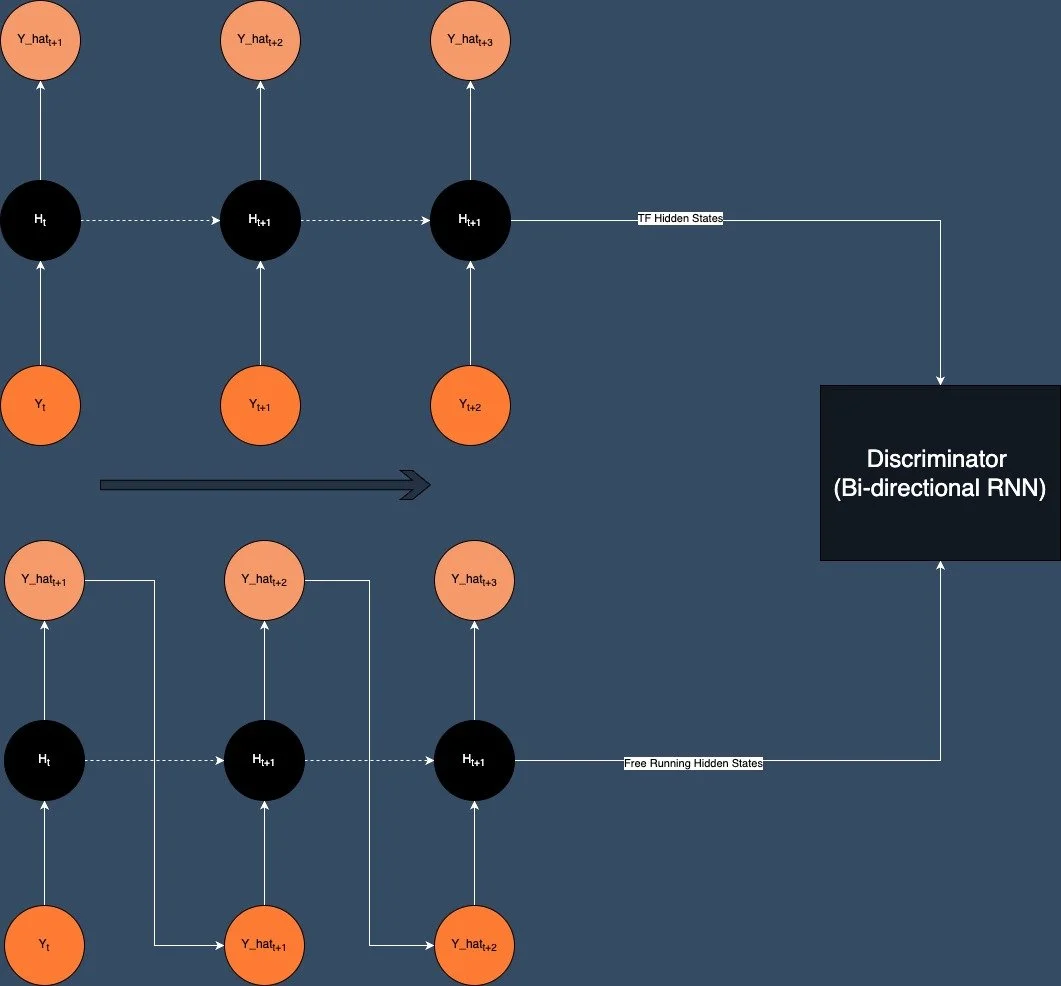
Professor Forcing
6. Attention Forcing
A novel approach proposed in 2020 [7] uses an attention mechanism. Unlike the standard teacher forcing, attention forcing guides the model with generated output history and reference attention, making training stable without the need for a schedule or a discriminator. "The basic idea is to use reference attention (i.e. reference alignment) and generated output to guide the model during training". From what I can understand the attention mechanism is used to align the ground truth output (reference output) to the input at each timestep.
7. Final Thoughts
So there's 5 ways to train a sequence model. Teacher Forcing is by far the simplest approach, but potentially leads to weaker models. Free Running is more difficult to train but should lead to more robust models. The other approaches try to find a middle ground between the two. I'd also like to try the approach proposed by [8] which somehow uses variational inference in the training process.
From my own personal experience I have experimented with free running and scheduled sampling but I have to admit that I've not had much success with either as the gradients do the neural network equivalent of a Harry Houdini disappearing act as I watch on and look at a bunch of NaNs spewing out of my loss function. As a result I have always reverted back to teacher forcing and accept that myopic and brittle is a necessary evil. Having said that most of my work with auto-regressive models has been in the time series domain and generally I have found that the models perform well and are comparable to benchmarks such as ETS.
References
- A Learning Algorithm for Continually Running Fully Recurrent Neural Networks
- NeurIPS 2018: Deep Unsupervised Learning
- DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
- Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
- Effective Teaching for Time Series Forecasting
- Professor Forcing: A New Algorithm for Training Recurrent Networks
- ATTENTION FORCING FOR SEQUENCE-TO-SEQUENCE MODEL TRAINING
- Deep State Space Models for Unconditional Word Generation